Rekurrens neurális hálózatok (RNN) – amikor a gépek „emlékezni” kezdenek
A mesterséges intelligencia és a gépi tanulás fejlődéstörténetében számos olyan mérföldkő található, amely gyökeresen megváltoztatta a kutatás irányát és lehetőségeit. A rekurrens neurális hálózatok (Recurrent Neural Networks, RNN-ek) pontosan ilyenek: megjelenésük áttörést jelentett minden olyan területen, ahol az adatok nem elszigetelten, hanem időben egymás után következő sorozatokban jelentek meg.
A klasszikus neurális hálózatok (feedforward) úgy működnek, hogy egy adott bemenetet közvetlenül egy adott kimenetté alakítanak. Ez jól használható képfelismerésnél vagy osztályozási feladatoknál, de teljesen elégtelen, ha a bemenetek időben összefüggő struktúrák. Gondoljunk csak egy mondatra: a szavak önmagukban is hordoznak jelentést, de valódi értelmük csak az előző és következő szavak kontextusában érthető meg. Egy klasszikus hálózat képtelen „emlékezni” arra, mi hangzott el néhány lépéssel korábban, egy RNN viszont pontosan erre képes.
Ez az emlékező képesség nyitotta meg az utat a beszédfelismerés, a gépi fordítás, a szöveggenerálás és az idősor-elemzés modern rendszerei előtt.
Az RNN-ek helye a mesterséges neurális hálózatok között
A mesterséges neurális hálózatokban a rekurrens neurális hálózatokat (RNN) kifejezetten szekvenciális adatok feldolgozására tervezték – ilyen például a szöveg, a beszéd, a zenei dallamok vagy az idősorok. Ezekben az adatokban az elemek sorrendje meghatározó, ezért az egyszerű előrecsatolt hálózatokkal szemben az RNN-ek előnye, hogy képesek figyelembe venni a kontextust.
A működés kulcsa a rekurrens kapcsolat: az egyik időpillanatban képzett kimenet visszacsatolódik bemenetként a következő időpillanatba. Így a hálózat folyamatosan frissíti belső „emlékezetét”, az ún. rejtett állapotot (hidden state). Ez egyfajta memória, amely minden lépésnél az aktuális bemenet és a múltbeli állapot kombinációjaként alakul ki.
Ennek köszönhetően az RNN képes:
- felismerni ismétlődő mintákat,
- kontextusfüggő döntéseket hozni,
- és hosszabb folyamatokat modellezni.
Ez tette lehetővé a szegmentálatlan kézírás-felismerést, a folyamatos beszédfelismerést és a neurális gépi fordítást – olyan feladatokat, amelyek klasszikus hálózatokkal megoldhatatlanok lettek volna.
Történeti áttekintés
Az ötlet, hogy egy hálózat képes legyen visszacsatolni az előző lépésekből származó információkat, már a 1980-as években megszületett. John Hopfield (1982) által bemutatott Hopfield-hálók például statikus asszociatív memóriaként működtek, de inspirációt adtak a dinamikus memóriával rendelkező rendszerekhez is.
Az igazi áttörés azonban 1986-ban következett be, amikor David Rumelhart, Geoffrey Hinton és Ronald Williams publikálták a híres cikküket, amelyben bemutatták a backpropagation through time (BPTT) algoritmust. Ez volt az a módszer, amellyel először sikerült hatékonyan tanítani a rekurrens hálózatokat.
A kezdeti lelkesedés azonban hamar problémákba ütközött: kiderült, hogy a klasszikus RNN-ek nehezen kezelik a hosszú távú összefüggéseket. Az ún. „eltűnő gradiens” probléma miatt a hálózatok képtelenek voltak több tucat vagy száz időlépésnyi információt visszakeresni. Ez a korlát majdnem évtizedekre visszavetette az RNN-kutatásokat.
Csak a 1990-es évek végén jött el az igazi fordulópont, amikor Sepp Hochreiter és Jürgen Schmidhuber (1997) bemutatták a Long Short-Term Memory (LSTM) architektúrát. Ez az új modell olyan kapuzási mechanizmusokat alkalmazott, amelyek képesek voltak a fontos információkat megőrizni, a feleslegeseket pedig elfelejteni. Az LSTM jelentőségét talán csak a perceptron feltalálásához lehet hasonlítani: teljesen új kutatási korszakot nyitott meg.
- 1940–50-es évek – Az alapgondolat megszületik: a gépek képesek lehetnek időben változó folyamatok modellezésére.
- 1980-as évek – John Hopfield bemutatja a Hopfield-hálót, amely előfutárként szolgált a dinamikus memóriát kezelő rendszerekhez.
- 1986 – Rumelhart, Hinton és Williams publikálják a backpropagation through time (BPTT) algoritmust, amely először tette lehetővé az RNN-ek hatékony tanítását.
- 1997 – Hochreiter és Schmidhuber kifejlesztik a Long Short-Term Memory (LSTM) architektúrát, amely megoldotta az eltűnő gradiens problémát.
- 2014 – Cho és társai bemutatják a Gated Recurrent Unit (GRU) modellt, amely egyszerűbb és számítási szempontból hatékonyabb, mint az LSTM.
- 2017 után – a transzformátorok megjelenésével az RNN-ek háttérbe szorultak, de továbbra is relevánsak bizonyos feladatoknál.
Működési elv
Az RNN egyik legfontosabb sajátossága a rejtett állapot fenntartása.
Matematikailag:
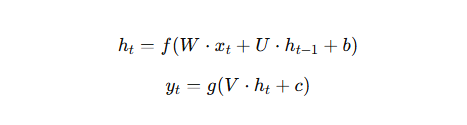
ahol:

Tanítási kihívások
A tanítás a BPTT algoritmussal történik, amely visszafelé terjeszti a hibát több időpillanaton keresztül. Ez azonban két problémát okoz:
Eltűnő gradiens – a súlyok változása olyan kicsi lesz, hogy a hálózat nem tanul a távoli múlt eseményeiből.
Robbanó gradiens – a gradiens túl nagyra nőhet, instabillá téve a tanítást.
Megoldások:
- gradiens-klippelés,
- súly-inicializálási stratégiák,
- LSTM és GRU használata.
LSTM és GRU
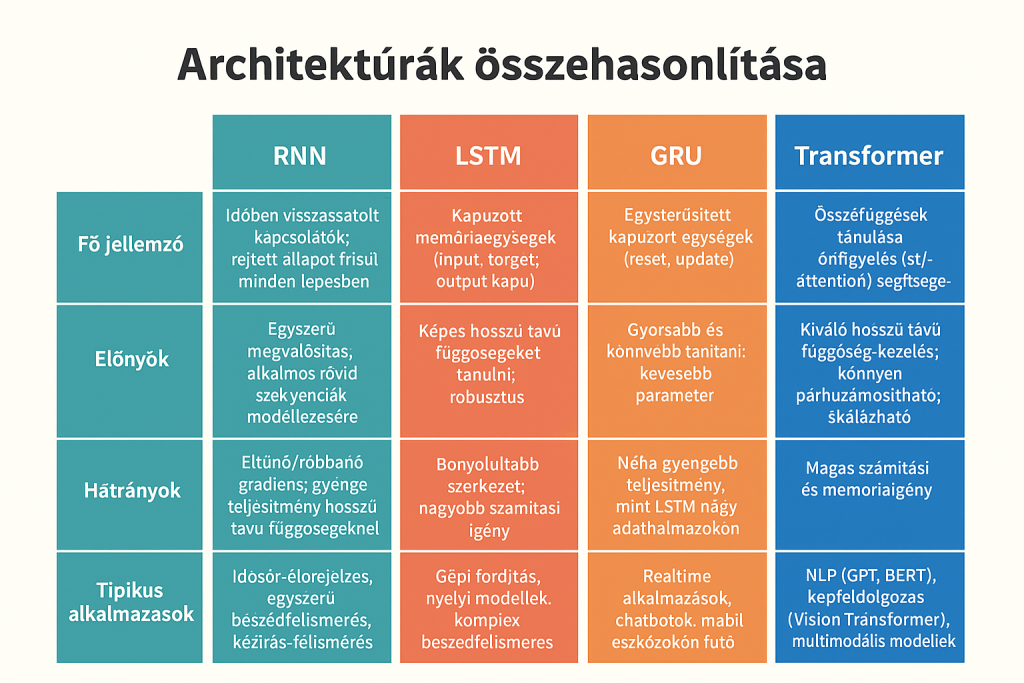
LSTM (1997) – bevezeti az input, forget és output kapukat, amelyek szabályozzák, milyen információt őrizzen meg, felejtsen el, vagy adjon tovább a hálózat.
GRU (2014) – egyszerűbb szerkezet, két kapuval (reset és update). Gyorsabb és sokszor hasonlóan pontos, mint az LSTM.
Konfigurációk és architektúrák
A rekurrens hálózatok többféle konfigurációban léteznek:
Standard RNN – az alapmodell, amely sorban dolgozza fel a bemenetet, és a rejtett állapotot továbbítja.
Halmozott RNN (Stacked RNN) – több RNN-réteget egymásra helyeznek, így mélyebb reprezentációkat képes tanulni.
Kétirányú RNN (Bidirectional RNN) – az adatok feldolgozása előre és visszafelé is megtörténik, így a modell nemcsak a múltat, hanem a jövőt is figyelembe veszi. Különösen hatékony pl. beszédfelismerésnél.
Kódoló–dekódoló (Encoder–Decoder) – az egyik RNN „összefoglalja” a bemeneti szekvenciát, a másik pedig kimeneti szekvenciát állít elő belőle. Ez a neurális gépi fordítás alapja.
PixelRNN – speciális RNN, amely képek pixeleit szekvenciaként dolgozza fel, előrejelzi a következő pixel értékét. Alkalmazták képgenerálásban is.
Alkalmazások
Beszédfelismerés – valós idejű diktafonok, digitális asszisztensek.
Természetes nyelvfeldolgozás – nyelvi modellek, szöveggenerálás, chatbotok.
Idősor-elemzés – gazdasági, időjárási előrejelzések.
Biológia – genetikai szekvenciák elemzése.
Kreatív feladatok – zene- és képgenerálás (PixelRNN).
Az RNN-ek és a transzformerek
Az utóbbi években a transzformátor architektúrák váltak uralkodóvá (pl. GPT, BERT). Ezek nem rekurziót, hanem önfigyelő (self-attention) mechanizmusokat használnak. Ennek előnye:
- jobban kezelik a hosszú távú összefüggéseket,
- könnyen párhuzamosíthatók,
- ipari méretekben is hatékonyak.
Mindazonáltal az RNN-ek ma is relevánsak:
- ha a valós idejű feldolgozás elsődleges,
- ha alacsony számítási költség a cél,
- vagy ha a szekvenciális feldolgozás természeténél fogva indokolt.
Hivatkozások
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
- Cho, K. et al. (2014). Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- Olah, C. (2015). Understanding LSTMs
- Stanford CS231n notes: RNNs and LSTMs