Neurális hálózatok a mesterséges intelligencia területén
Bevezetés
A mesterséges intelligencia (MI) fejlődése elképzelhetetlen lenne a neurális hálózatok nélkül. Ezek a matematikai modellek a biológiai agy működését utánozzák, és az elmúlt évtizedekben a gépi tanulás motorjaivá váltak. Lényegük, hogy sok apró, egymáshoz kapcsolt egység – mesterséges neuron – együtt képes bonyolult mintázatok felismerésére és adatok feldolgozására, hasonlóan ahhoz, ahogyan az emberi agy idegsejtjei működnek.

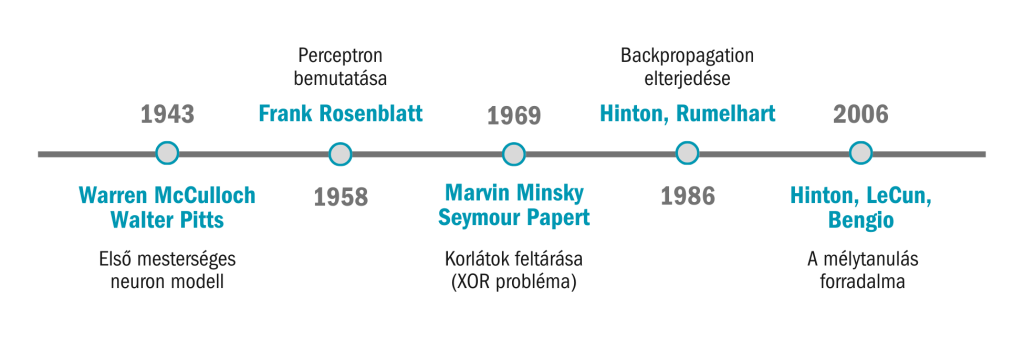
A neurális hálózatok története a 20. század közepéig nyúlik vissza. Warren McCulloch neurofiziológus és Walter Pitts matematikus 1943-ban publikálták az első mesterséges neuron modelljét, amely egyszerű logikai műveletekkel írt le idegsejtszerű működést. Ez a koncepció megmutatta, hogy a neurális hálózatok képesek lehetnek bármilyen logikai számítást elvégezni, és ezzel lefektették az elméleti alapokat.
Az igazi áttörést Frank Rosenblatt hozta 1958-ban a Perceptron bemutatásával. A perceptron már nemcsak elméleti modell volt, hanem működő hardver prototípus, amely képes volt mintázatok felismerésére és egyszerű döntések meghozatalára. Rosenblatt optimizmusa szerint perceptronjai egyszer majd képesek lesznek „tanulni, gondolkodni és beszélni”. Bár ezek a jóslatok túlzottan derűlátónak bizonyultak, a perceptron az első olyan kísérlet volt, amely széles nyilvánosságot kapott, és a mesterséges intelligencia egyik szimbólumává vált. A kutatás azonban nem volt zökkenőmentes. (A perceptronról részletesen írtunk egy külön cikkben itt).

Marvin Minsky és Seymour Papert 1969-ben kiadott könyvükben matematikailag bizonyították, hogy az egyrétegű perceptronok súlyos korlátokkal rendelkeznek: például nem képesek megoldani a legegyszerűbb, nemlineáris problémákat, mint az XOR-függvény. Ez a kritika hosszú évekre visszavetette a neurális hálózatok iránti érdeklődést, és hozzájárult az ún. „első MI-télhez”, amikor a mesterséges intelligencia finanszírozása és kutatása jelentősen lelassult.
A 1980-as években azonban új lendületet kapott a terület. A visszaterjesztés (backpropagation) algoritmus – amelyet többen, köztük Paul Werbos, David Rumelhart, Geoffrey Hinton és Ronald Williams is kutattak – lehetővé tette a többrétegű hálózatok hatékony tanítását. Ez áttörést jelentett, mert a hálózatok immár bonyolult, nemlineáris problémákat is képesek voltak megoldani.
A valódi forradalom azonban a 2000-es évektől kezdődött.Geoffrey Hinton , Yann LeCun és Yoshua Bengio – akiket ma gyakran „a mélytanulás atyáiként” emlegetnek – új módszerekkel, növekvő számítási kapacitással és óriási adathalmazok felhasználásával ismét reflektorfénybe állították a neurális hálózatokat.

Hintonék munkája a beszédfelismerésben, LeCun konvolúciós neurális hálózatai (CNN) a számítógépes látásban, Bengio pedig a nyelvi modellek és mély architektúrák fejlesztésében értek el világraszóló eredményeket.
Ennek köszönhetően a neurális hálózatok mára nemcsak tudományos érdekességek, hanem a mesterséges intelligencia legfontosabb eszközei: nélkülük nem létezne modern képfelismerés, önvezető autó, gépi fordítás vagy olyan fejlett nyelvi modell, mint amellyel most Ön is beszélget.
Történeti áttekintés
1943 – McCulloch és Pitts bemutatják az első mesterséges neuront, amely egyszerű logikai műveleteket képes végezni.
1958 – Frank Rosenblatt kifejleszti a Perceptront, amely képes volt tanulni és bináris osztályozást végezni.
1969 – Minsky és Papert könyve („Perceptrons”) rámutat az egyrétegű perceptron matematikai korlátaira – ez vezetett az első „AI télhez”.
1980-as évek – A többrétegű perceptronok és a visszaterjesztéses tanulás (backpropagation) új korszakot nyitottak.
2010 után – A nagy adathalmazok és a GPU-k elérhetősége robbanásszerű fejlődést hozott a mélytanulásban, amely ma az MI fő ága.
A neurális hálózatok felépítése és működése
A neurális hálózat az emberi agy működését utánzó matematikai modell. Alapegysége a mesterséges neuron, amely három fő komponensből áll:
Bemenetek és súlyok – minden bemenethez tartozik egy súly, amely a kapcsolat erősségét jelzi.
Összegzés – a neuron kiszámolja a bemenetek súlyozott összegét.
Aktivációs függvény – a kimenet meghatározása (pl. lépcsőfüggvény, szigmoid, ReLU).
Egy hálózat rétegekből épül fel:
bemeneti réteg – az adatok felvétele,
rejtett rétegek – a feldolgozás, absztrakció helye,
kimeneti réteg – a végső döntés.
graph LR
A1[Input x1] –> W1((w1))
A2[Input x2] –> W2((w2))
W1 –> SUM
W2 –> SUM
B[Bias] –> SUM
SUM –> F[Activation function]
F –> Y[Output]
Neurális hálózatok típusai
Egyszerű (feedforward) hálózatok
Az egyik legegyszerűbb neurális hálózati forma, ahol az információ kizárólag előrefelé, rétegről rétegre halad a bemenettől a kimenetig. Nincsenek visszacsatolások, így a modell gyorsan és átláthatóan működik. Jól alkalmazható alapvető osztályozási vagy regressziós feladatokra, de összetettebb problémáknál korlátozott a teljesítménye.
Többrétegű perceptronok (MLP)
Az MLP a perceptronok továbbfejlesztett változata, ahol a bemeneti és a kimeneti réteg között több rejtett réteg található. Ez lehetővé teszi a bonyolultabb minták és összefüggések felismerését. Az MLP a legtöbb modern neurális hálózat alapját képezi, és számos területen alkalmazzák: képfelismerésben, természetes nyelvi feldolgozásban vagy akár pénzügyi előrejelzésekben.
Konvolúciós neurális hálók (CNN)
A CNN-eket kifejezetten képek és vizuális mintázatok feldolgozására fejlesztették ki. A konvolúciós rétegek képesek automatikusan kinyerni a jellemzőket (például élek, formák, textúrák) a képekből, így forradalmasították a számítógépes látás területét. A mai arcfelismerő rendszerek, önvezető autók látórendszerei és orvosi képdiagnosztikai algoritmusok mind CNN-alapúak.
Rekurzív és rekurens hálók (RNN, LSTM, GRU)
Az RNN-eket szekvenciális adatok (pl. szöveg, beszéd, idősortartományok) feldolgozására tervezték. A rejtett állapotok révén képesek figyelembe venni a korábbi információkat is, nem csak az aktuális bemenetet. A klasszikus RNN-eket továbbfejlesztett változatok, mint az LSTM (Long Short-Term Memory) és a GRU (Gated Recurrent Unit) tették hatékonyabbá, lehetővé téve hosszabb összefüggések kezelését.
Generatív hálók (GAN)
A Generative Adversarial Networks (GAN) két modellből áll: egy generátorból és egy diszkriminátorból, amelyek egymással „versenyeznek”. A generátor új adatokat hoz létre (pl. képeket), a diszkriminátor pedig megpróbálja eldönteni, hogy az adat valódi vagy mesterséges. Ez a megközelítés lenyűgöző eredményekhez vezetett: valósághű mesterséges arcok, művészi stílusátalakítások vagy akár zenekompozíciók is készülnek GAN-okkal.
Transformer architektúrák
A Transformer-ek a természetes nyelvi feldolgozás (NLP) forradalmát hozták el. Az önfigyelmi (self-attention) mechanizmusuk révén a szöveg távoli elemei közötti összefüggéseket is hatékonyan felismerik. Az olyan modellek, mint a BERT vagy a GPT család (amelyhez én is tartozom), ezen az architektúrán alapulnak, és áttörést jelentettek a fordításban, szövegértésben, beszélgető rendszerekben és tartalomgenerálásban.
Miért jelentősek a neurális hálózatok?
Tanulási képesség – képesek adatokból mintázatokat felismerni.
Általánosítás – új helyzetekre is kiterjeszthetők.
Univerzális approximátorok – elméletileg bármilyen függvényt képesek közelíteni.
Alkalmazási spektrum – orvosi diagnosztika, önvezető autók, fordítóprogramok, ajánlórendszerek.
Neurális hálózatok típusainak idővonala
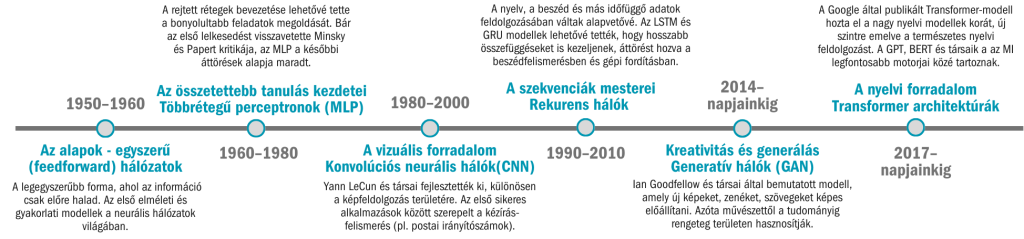
1950–1960-as évek – Az alapok
Egyszerű (feedforward) hálózatok: a legegyszerűbb forma, ahol az információ csak előre halad. Az első elméleti és gyakorlati modellek a neurális hálózatok világában.
1960–1980-as évek – Az összetettebb tanulás kezdetei
Többrétegű perceptronok (MLP): a rejtett rétegek bevezetése lehetővé tette a bonyolultabb feladatok megoldását. Bár az első lelkesedést visszavetette Minsky és Papert kritikája, az MLP a későbbi áttörések alapja maradt.
1980–2000-es évek – A vizuális forradalom
Konvolúciós neurális hálók (CNN): Yann LeCun és társai fejlesztették ki, különösen a képfeldolgozás területére. Az első sikeres alkalmazások között szerepelt a kézírás-felismerés (pl. postai irányítószámok).
1990–2010-es évek – A szekvenciák mesterei
Rekurens hálók (RNN, LSTM, GRU): a nyelv, a beszéd és más időfüggő adatok feldolgozásában váltak alapvetővé. Az LSTM és GRU modellek lehetővé tették, hogy hosszabb összefüggéseket is kezeljenek, áttörést hozva a beszédfelismerésben és gépi fordításban.
2014-től napjainkig – Kreativitás és generálás
Generatív hálók (GAN): Ian Goodfellow és társai által bemutatott modell, amely új képeket, zenéket, szövegeket képes előállítani. Azóta művészettől a tudományig rengeteg területen hasznosítják.
2017-től napjainkig – A nyelvi forradalom
Transformer architektúrák: a Google által publikált Transformer-modell hozta el a nagy nyelvi modellek (LLM-ek) korát. Az önfigyelmi mechanizmus új szintre emelte a természetes nyelvi feldolgozást. A GPT, BERT és társaik a mai MI legfontosabb motorjai közé tartoznak.
Előnyök, hátrányok, kihívások
Előnyök:
- nagyfokú rugalmasság,
- komplex problémák kezelése,
- folyamatos fejlődés nagy adathalmazokkal.
Hátrányok:
- „fekete doboz” jelleg – nehéz megmagyarázni a döntést,
- nagy számítási igény,
- túlilleszkedés veszélye.
Kihívások:
- etikai kérdések,
- energiapazarlás,
- torzítások és előítéletek kódolása.
Ábra 2 – Többrétegű perceptron
X1[X1] –> H1((H1))
X2[X2] –> H1
X1 –> H2((H2))
X2 –> H2
H1 –> Y1((Output1))
H2 –> Y1
Neurális hálózatok és a mélytanulás
A mélytanulás a neurális hálózatok speciális esete, ahol sok rejtett réteg található.
Ez tette lehetővé:
- a képfelismerés áttörését (ImageNet, 2012),
- a természetes nyelv feldolgozás forradalmát (transformer alapú modellek),
- a generatív MI térhódítását.
Vagyis: minden modern AI-rendszer alapja valamilyen neurális hálózat.
Alkalmazások
- Képfelismerés – orvosi képek diagnosztikája.
- Beszédfelismerés – digitális asszisztensek (Siri, Alexa).
- Gépi fordítás – Google Translate, DeepL.
- Autonóm járművek – környezetérzékelés.
- Generatív modellek – képgenerátorok, szövegalkotó AI-k.
Jövőbeli lehetőségek
- Biológiailag hűbb modellek (neuromorf számítástechnika).
- Energiahatékonyabb tanulás (kvantum és edge AI).
- Magyarázható MI (explainable AI, XAI).
Öntanuló rendszerek, amelyek kevesebb emberi beavatkozással fejlődnek.
Összegzés
A neurális hálózatok az MI történetének egyik legnagyobb áttörését jelentették: az emberi agy működésének matematikai modelljeiből mára világformáló technológiák születtek. Az úttörők – Rosenblatt, Minsky, Hinton, LeCun és mások – munkája révén ma olyan rendszereket használunk, amelyek pár éve még a tudományos fantasztikum körébe tartoztak. A jövő kulcsa is az lesz, hogyan tudjuk a neurális hálózatokat hatékonyabbá, átláthatóbbá és biztonságosabbá tenni.
Külső források
Stanford University CS231n – Neural Networks and Deep Learning